
Scaling AI Solutions: From Prototype to Production Best Practices
Learn how to successfully scale AI solutions from prototype to production, focusing on key practices that align data engineering with business goals, especially in healthcare.
Scaling AI Solutions: Best Practices from Prototype to Production
Scaling AI solutions from prototype to production is a critical challenge for modern businesses. While many organizations celebrate early success with proofs of concept, they often encounter engineering, data, compliance, and operational complexities that hinder further progress.
The reality is stark: According to industry research, up to 87% of AI projects never make it from prototype to production. This high failure rate isn't due to a lack of innovation—it's because scaling AI requires fundamentally different disciplines than building prototypes.
This comprehensive guide outlines a practical framework for scaling AI solutions successfully, with a particular focus on healthcare applications where the stakes are highest. We'll explore how to align data engineering with business KPIs, structure modular production pipelines, ensure proper observability, and build clear handoff practices between prototyping and engineering teams.
Understanding the Prototype-to-Production Challenge
An AI prototype is a proof of concept that demonstrates feasibility; a production system is an engineered solution that delivers consistent business value at scale. The gap between these two states represents one of the most complex technical and organizational challenges in modern business transformation.
The prototype phase typically involves data scientists working with curated datasets, flexible environments, and tolerance for experimental approaches. Production systems, however, must handle real-world data variability, maintain consistent performance, integrate with existing systems, and operate under strict governance requirements.
Research from IBM indicates that organizations face six primary challenges when scaling AI: data privacy concerns, high implementation costs, resistance to organizational change, integration with legacy systems, skills gaps, and measuring return on investment. Each of these challenges requires specific strategies and frameworks to address effectively.
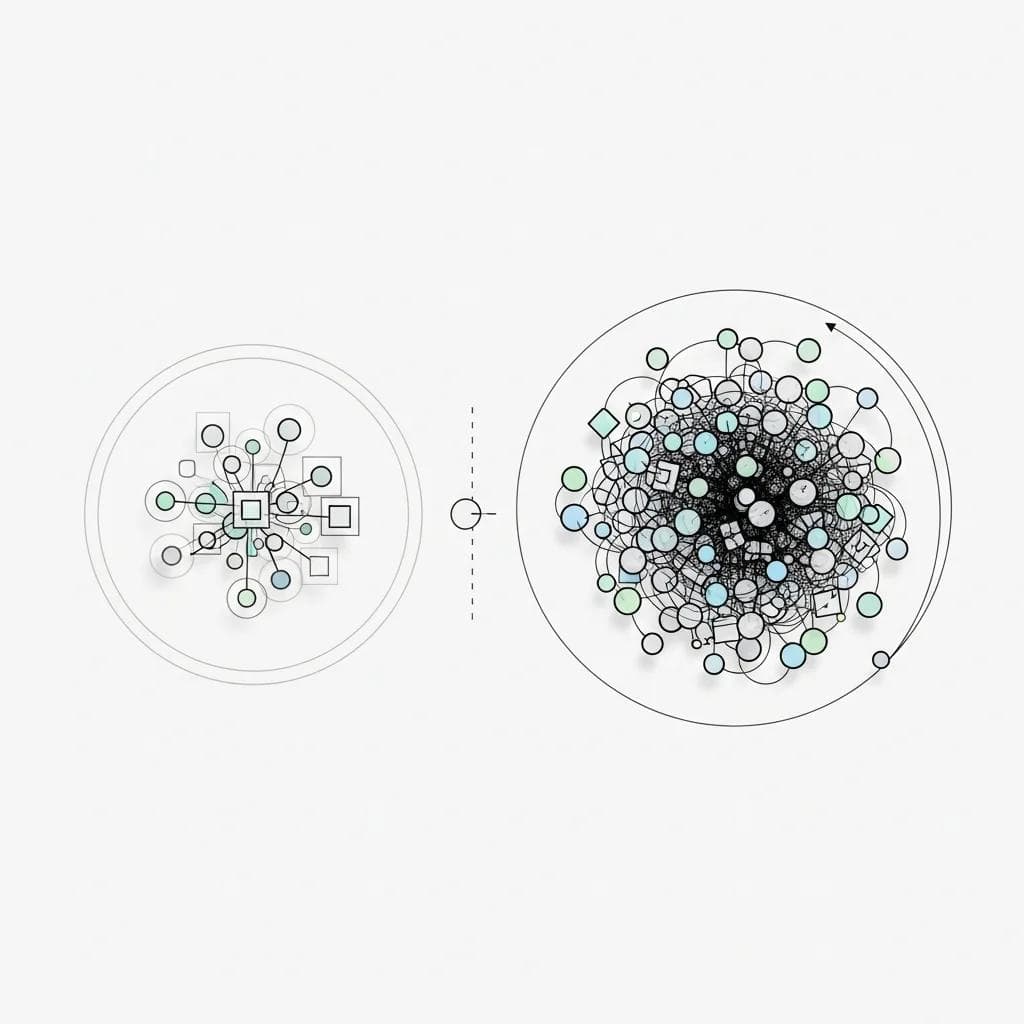
Diagram showing the complexity gap between AI prototype and production environments.
The healthcare sector exemplifies these challenges particularly well. A diagnostic AI prototype might achieve impressive accuracy on a research dataset, but production deployment requires HIPAA compliance, integration with electronic health records, real-time performance standards, and fail-safe mechanisms that protect patient safety.
How to Scale AI Solutions in Healthcare
Scaling AI solutions in healthcare begins with aligning data engineering with clinical workflows and ensuring compliance with healthcare regulations. This involves structuring data flows to support clinical decision-making timelines and integrating real-time data for emergency department AI systems.
Effective data engineering for AI production involves implementing data quality monitoring that directly correlates with business metrics. For example, if an AI system supports clinical diagnosis, data quality metrics should track completeness of patient records, timeliness of lab results, and consistency of imaging data—all factors that directly impact diagnostic accuracy.
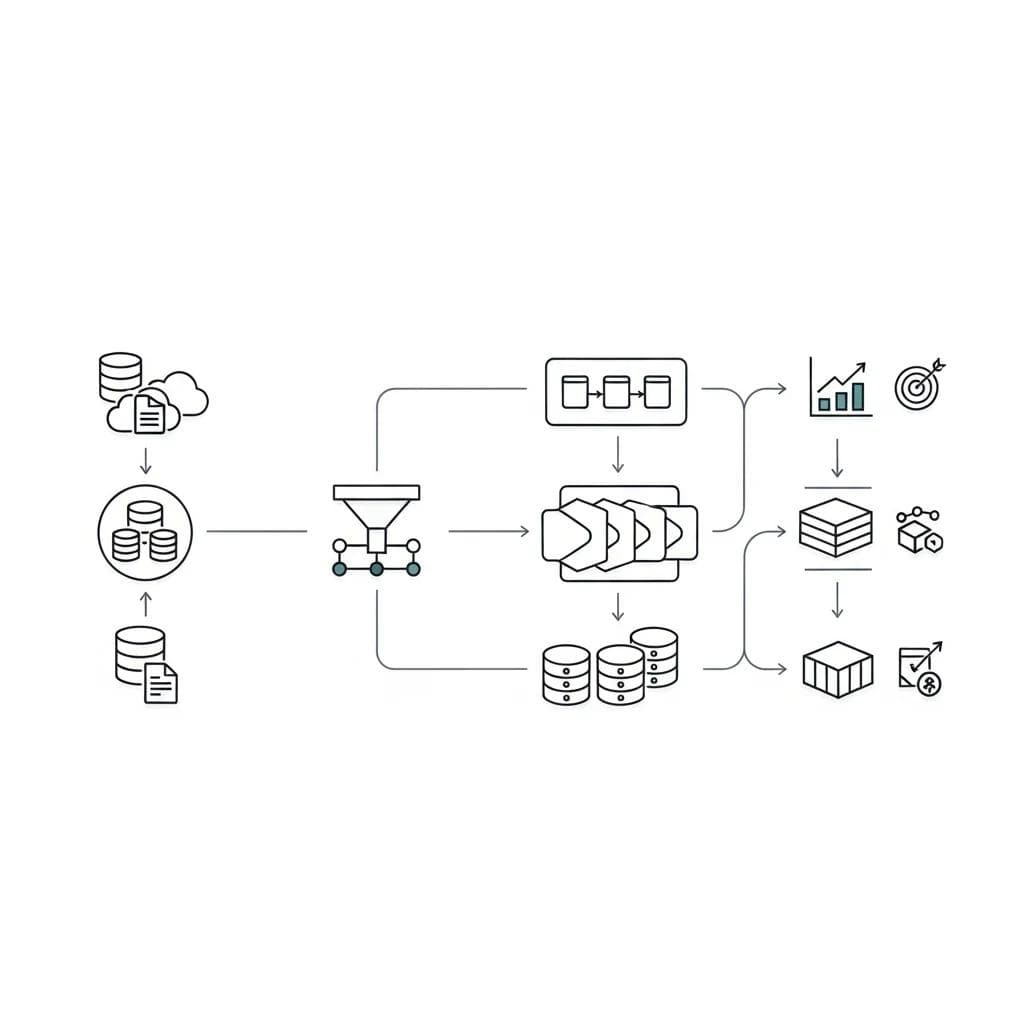
Flowchart showing data engineering pipeline aligned with business KPIs.
The Strategic Framework for Scaling AI Solutions
Phase 1: Production Readiness Assessment
Before transitioning any AI solution from prototype to production, organizations must conduct a comprehensive readiness assessment. This evaluation encompasses technical, operational, and business dimensions.
Technical readiness involves evaluating model performance across diverse datasets, not just the curated data used during prototyping. Production models must maintain accuracy when encountering data drift, edge cases, and real-world variability that controlled experiments don't capture.
Infrastructure requirements often surprise organizations during scaling. A prototype running on a data scientist's laptop requires entirely different architecture when serving thousands of users simultaneously. Cloud-native solutions, containerization, and microservices architectures become essential for handling production loads.
Operational readiness means establishing clear ownership, support processes, and escalation procedures. Unlike prototypes managed by research teams, production systems require 24/7 monitoring, incident response capabilities, and defined service level agreements.
Phase 2: Data Engineering Alignment with Business KPIs
Data engineering for production AI systems must be architected around business outcomes, not technical convenience. This fundamental shift requires aligning data pipelines with specific key performance indicators that matter to stakeholders.
In healthcare applications, this might mean structuring data flows to support clinical decision-making timelines rather than batch processing schedules that work for research. Emergency department AI systems need real-time data integration, while population health analytics can operate on daily updates.
Effective data engineering for AI production involves implementing data quality monitoring that directly correlates with business metrics. For example, if an AI system supports clinical diagnosis, data quality metrics should track completeness of patient records, timeliness of lab results, and consistency of imaging data—all factors that directly impact diagnostic accuracy.
The modular approach to data architecture becomes crucial at scale. Rather than monolithic pipelines that served prototype development, production systems benefit from composable data services that can be independently updated, monitored, and scaled based on business priorities.
Flowchart showing data engineering pipeline aligned with business KPIs.
Phase 3: Building Modular, Testable Production Pipelines
Production AI pipelines must be designed for maintainability, not just functionality. This requires adopting software engineering best practices that many data science teams haven't traditionally emphasized.
Modular design principles apply to every component of the AI system. Model training, data preprocessing, feature engineering, and inference serving should be independent services with well-defined interfaces. This modularity enables teams to update individual components without risking system-wide failures.
Testing strategies for AI systems extend beyond traditional software testing to include data validation, model performance monitoring, and business logic verification. Automated testing pipelines should validate data quality, model accuracy, and system integration at every deployment stage.
Version control becomes critical when managing multiple models, datasets, and configurations. Production systems need clear lineage tracking that connects business outcomes to specific model versions, training data, and configuration settings.
Container orchestration platforms like Kubernetes provide the infrastructure foundation for modular AI systems. These platforms enable independent scaling of different pipeline components based on demand and resource requirements.
Implementing Observability and Model Monitoring
Observability in AI systems means having real-time visibility into model performance, data quality, and business impact—not just system uptime. Traditional application monitoring tools aren't sufficient for AI systems because they can't detect model drift, bias emergence, or gradual performance degradation.
Model monitoring requires tracking multiple dimensions simultaneously. Accuracy metrics show whether predictions remain reliable, but production systems also need to monitor prediction confidence, input data distribution changes, and correlation with business outcomes.
Data drift detection is essential for maintaining AI system reliability over time. Production environments experience constant changes in user behavior, external conditions, and data sources that can gradually degrade model performance without obvious system failures.
Healthcare AI systems exemplify the importance of comprehensive monitoring. A diagnostic AI system might maintain technical functionality while experiencing accuracy drift due to changes in patient populations, imaging equipment, or clinical protocols. Robust monitoring systems detect these changes before they impact patient care.
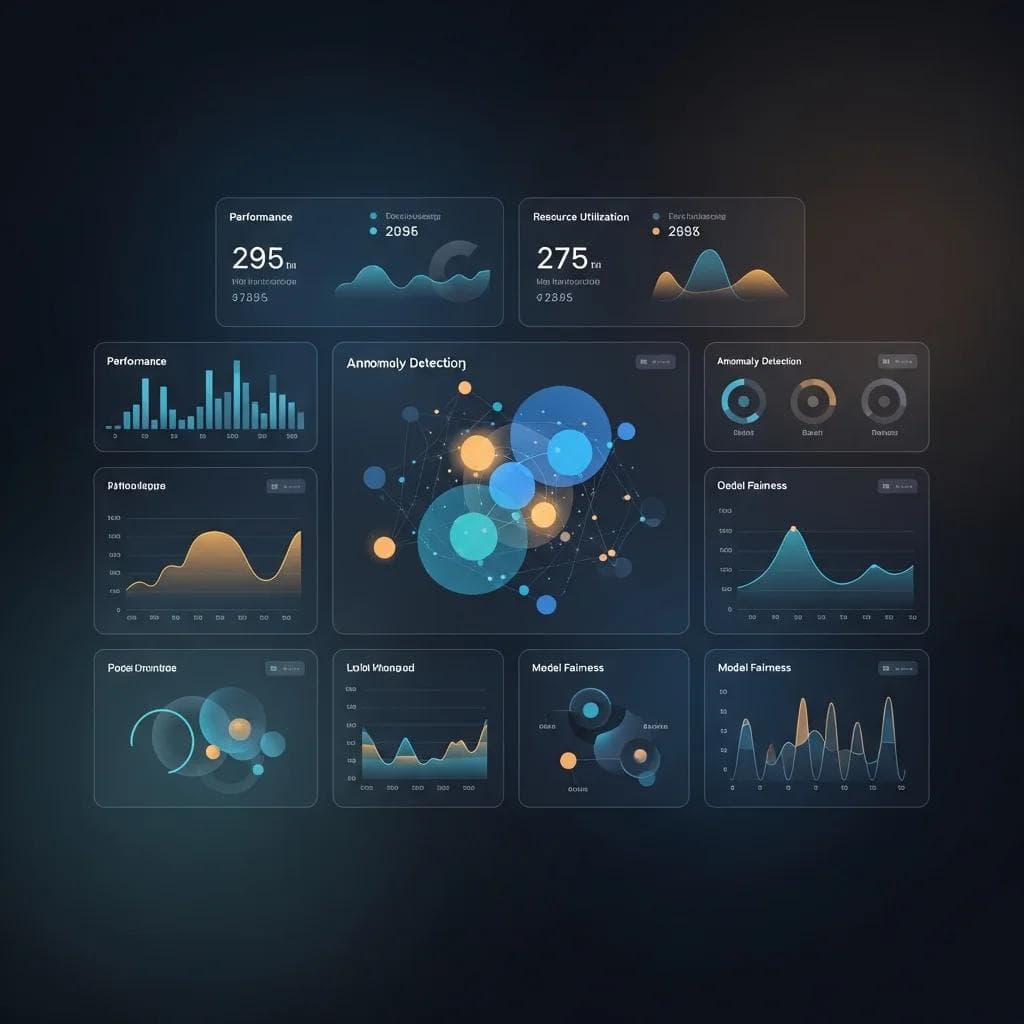
Dashboard showing comprehensive AI system observability metrics.
Alert systems for AI applications must balance sensitivity with actionability. Too many alerts create noise that teams ignore; too few alerts miss critical issues. Effective monitoring strategies establish clear thresholds tied to business impact and escalation procedures that ensure rapid response.
Establishing Clear Handoff Practices
Successful AI scaling requires structured transition processes between research and engineering teams. The handoff from prototype to production represents a critical knowledge transfer point that determines long-term system success.
Documentation standards for AI handoffs must capture both technical specifications and business context. Production teams need to understand not just how the model works, but why specific design decisions were made and what business requirements drove those choices.
Model cards and data sheets provide standardized formats for communicating AI system characteristics to production teams. These documents should include model performance metrics, training data descriptions, known limitations, and recommended use cases.
Testing protocols during handoff should verify that production teams can successfully deploy, monitor, and maintain the AI system independently. This includes validating deployment procedures, confirming monitoring setup, and ensuring support teams understand escalation procedures.
Knowledge transfer sessions between research and engineering teams should focus on edge cases, failure modes, and troubleshooting approaches that aren't captured in formal documentation. This tacit knowledge often proves crucial for maintaining production systems.
Common Scaling Traps and How to Avoid Them
Neglecting Performance Benchmarks
Many organizations scale AI systems without establishing clear performance baselines that connect technical metrics to business outcomes. This oversight makes it impossible to determine whether production systems are delivering expected value.
Performance benchmarking for AI systems requires measuring both technical performance (latency, throughput, accuracy) and business performance (user satisfaction, process efficiency, revenue impact). These metrics must be tracked consistently from prototype through production deployment.
Healthcare applications demonstrate the importance of comprehensive benchmarking. A clinical decision support system might achieve excellent technical performance while failing to improve patient outcomes due to poor integration with clinical workflows.
Ignoring Governance Requirements
Governance requirements for production AI systems are fundamentally different from prototype constraints. Regulatory compliance, audit trails, and risk management become mandatory rather than optional considerations.
Healthcare AI systems must comply with HIPAA privacy requirements, FDA device regulations, and clinical documentation standards. These requirements significantly impact system architecture, data handling procedures, and deployment processes.
Effective AI governance frameworks establish clear approval processes for model updates, data changes, and system modifications. These processes ensure that production systems maintain compliance while enabling necessary evolution and improvement.
Misunderstanding Infrastructure Needs
Infrastructure requirements for production AI systems often exceed prototype needs by orders of magnitude. Organizations frequently underestimate the computational, storage, and networking resources required for reliable production operation.
Scalability planning must account for peak usage scenarios, not just average loads. Healthcare AI systems might experience sudden demand spikes during public health emergencies or seasonal illness patterns that require elastic infrastructure capabilities.
Cloud-native architectures provide the flexibility and scalability that most production AI systems require. However, cloud adoption introduces new considerations around data sovereignty, latency, and cost management that prototype environments don't address.
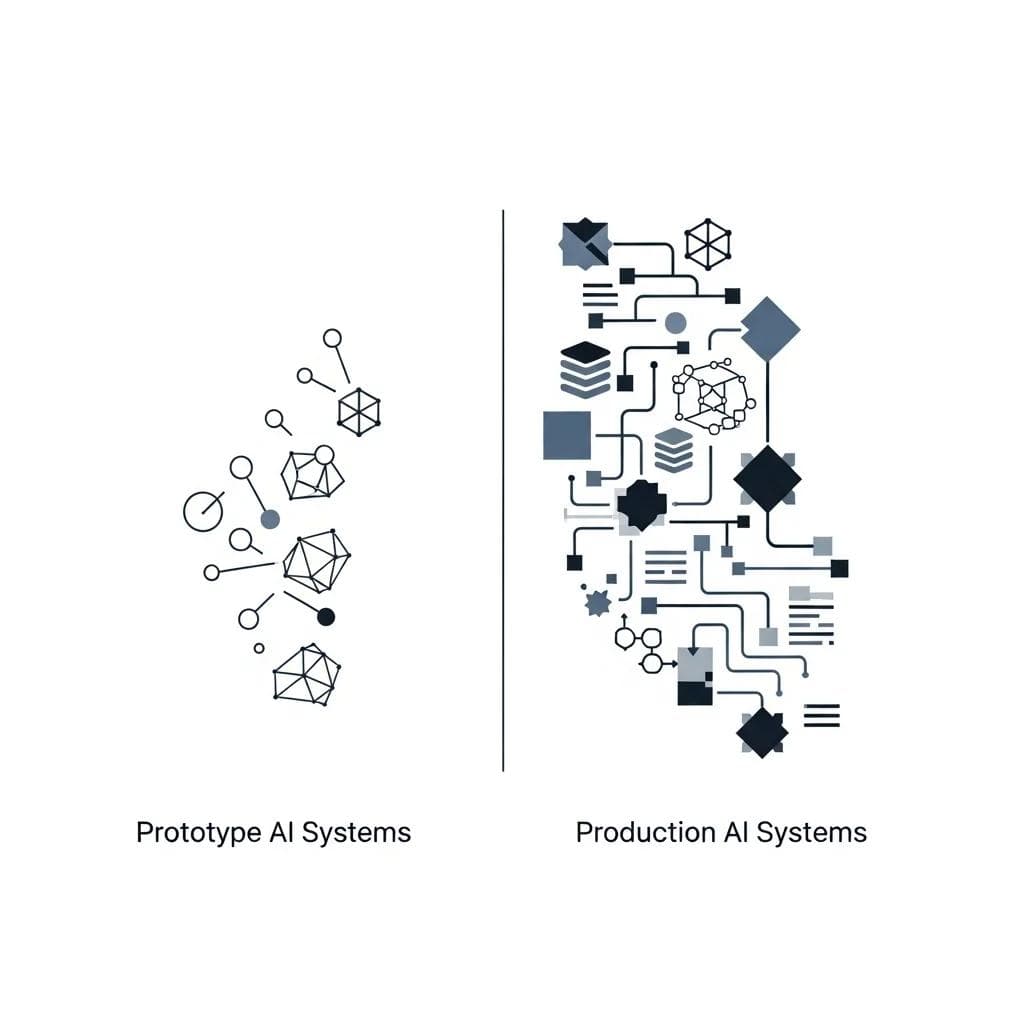
Comparison chart showing resource requirements for prototype vs production AI systems.
Agile Methodologies for AI Development at Scale
Agile practices for AI development must adapt traditional software development approaches to account for the experimental nature of machine learning and the iterative process of model improvement. Standard sprint cycles and delivery timelines don't always align with AI development realities.
Research from Forrester indicates that AIOps integration with DevOps practices can reduce development cycle times by up to 40% while improving collaboration between development and operations teams. This integration becomes particularly valuable when scaling AI systems that require frequent model updates and performance optimization.
AI-specific Agile practices include model versioning strategies, automated testing pipelines for machine learning components, and continuous integration workflows that validate both code and model performance. These practices ensure that teams can deploy AI updates safely and rapidly.
Sprint planning for AI teams should balance research exploration with production delivery commitments. Some sprints might focus on model experimentation and improvement, while others prioritize system reliability and operational excellence.
Retrospective practices for AI teams should examine both technical outcomes and business impact. Learning from model performance, user feedback, and operational challenges helps teams continuously improve their scaling practices.
Healthcare-Specific Scaling Considerations
Healthcare AI systems face unique scaling challenges due to regulatory requirements, patient safety concerns, and complex integration needs with existing clinical systems.
Clinical workflow integration represents one of the most critical success factors for healthcare AI scaling. Systems that require significant changes to established clinical practices face adoption resistance and implementation delays.
Patient data privacy and security requirements in healthcare exceed most other industries. HIPAA compliance, audit logging, and access controls must be embedded into every aspect of production AI systems, not added as afterthoughts.
Interoperability with electronic health record systems, medical devices, and clinical decision support tools requires standardized data formats and communication protocols. HL7 FHIR standards provide frameworks for healthcare data exchange, but implementation complexity often surprises teams transitioning from prototype environments.
Clinical validation requirements for healthcare AI systems may involve regulatory approval processes, clinical trials, and peer review that significantly extend scaling timelines. Organizations must plan for these requirements early in the scaling process.

Healthcare AI system architecture showing integration points with clinical systems.
Measuring Success: KPIs for AI Production Systems
Success metrics for production AI systems must encompass technical performance, business impact, and operational efficiency. Single-dimensional metrics like model accuracy provide incomplete pictures of system value.
Technical KPIs should track model performance stability over time, system availability and reliability, and resource utilization efficiency. These metrics help teams maintain system health and identify optimization opportunities.
Business impact metrics vary by application but should directly connect AI system performance to organizational outcomes. Healthcare AI systems might track improvements in diagnostic accuracy, reduction in clinical errors, or increases in operational efficiency.
Operational KPIs measure the effectiveness of scaling processes themselves. Time to deploy model updates, incident response times, and team productivity metrics help organizations improve their AI scaling capabilities.
User adoption and satisfaction metrics provide crucial feedback on whether AI systems are delivering value to end users. High technical performance means little if users don't trust or effectively utilize AI recommendations.
Building Organizational Capabilities for AI Scaling
Successful AI scaling requires developing organizational capabilities that extend beyond technical expertise. Teams need skills in project management, change management, and business analysis in addition to data science and engineering capabilities.
Cross-functional collaboration becomes essential when scaling AI systems. Data scientists, software engineers, business analysts, and domain experts must work together effectively to translate prototype insights into production value.
Training and development programs should prepare teams for the unique challenges of AI production systems. This includes technical skills like MLOps and model monitoring, as well as soft skills like stakeholder communication and change management.
Hiring strategies for AI scaling teams should balance deep technical expertise with broad operational experience. Teams need members who understand both the theoretical foundations of machine learning and the practical realities of production system management.
Knowledge management systems help organizations capture and share lessons learned from AI scaling projects. This institutional knowledge becomes increasingly valuable as organizations scale multiple AI initiatives simultaneously.
Frequently Asked Questions
What are the most common reasons AI projects fail during scaling?
The primary reasons include inadequate infrastructure planning, poor data quality management, lack of clear business alignment, insufficient operational support, and underestimating governance requirements. Organizations often focus too heavily on model performance while neglecting the engineering and operational disciplines required for production systems.
How long does it typically take to scale an AI prototype to production?
Scaling timelines vary significantly based on application complexity, regulatory requirements, and organizational readiness. Simple applications might scale in 3-6 months, while complex healthcare or financial services applications often require 12-18 months. The key is establishing realistic timelines that account for testing, compliance, and integration requirements.
What infrastructure considerations are most important for healthcare AI scaling?
Healthcare AI systems require HIPAA-compliant infrastructure, integration capabilities with electronic health records, real-time performance for clinical applications, robust security and audit logging, and disaster recovery capabilities. Cloud providers offer healthcare-specific services, but organizations must carefully evaluate compliance and data sovereignty requirements.
How do you measure ROI for scaled AI systems?
ROI measurement should combine direct cost savings, revenue improvements, and operational efficiency gains with longer-term benefits like improved decision-making and risk reduction. Healthcare AI systems might measure ROI through reduced diagnostic errors, improved patient outcomes, and increased operational efficiency rather than just cost savings.
What role do Agile methodologies play in AI scaling?
Agile practices help teams balance research exploration with production delivery, manage the iterative nature of AI development, and respond quickly to changing requirements. However, AI-specific adaptations are needed for model versioning, performance validation, and cross-functional collaboration between data science and engineering teams.
How do you handle model updates in production AI systems?
Model updates require robust versioning systems, automated testing pipelines, gradual rollout procedures, and rollback capabilities. Production systems should support A/B testing of model versions and maintain audit trails of all changes. Healthcare applications may require additional validation and approval processes for model updates.
What are the key differences between prototype and production AI architectures?
Production architectures emphasize reliability, scalability, maintainability, and security over experimental flexibility. This includes containerized deployments, microservices architecture, comprehensive monitoring, automated testing, and integration with enterprise systems. Data handling shifts from exploratory analysis to robust, automated pipelines.
How do you ensure AI system reliability in healthcare applications?
Healthcare AI reliability requires multiple safeguards including comprehensive testing across diverse patient populations, continuous monitoring for model drift and bias, integration with clinical decision support workflows, clear escalation procedures for system failures, and regular validation against clinical outcomes. Fail-safe mechanisms ensure patient safety even during system issues.
Conclusion: From Innovation to Impact
Scaling AI solutions from prototype to production represents a fundamental transformation in how organizations approach artificial intelligence. Success requires more than technical expertise—it demands engineering discipline, operational alignment, and clear transition processes that bridge the gap between research innovation and business value.
The organizations that succeed in AI scaling are those that treat production deployment as an engineering discipline, not an extension of research activities. They invest in robust infrastructure, comprehensive monitoring, and cross-functional teams that can maintain and evolve AI systems over time.
Healthcare applications demonstrate both the potential and challenges of AI scaling. The stakes are highest in healthcare, but so are the rewards for organizations that successfully navigate the complexity of production deployment.
Prototypes teach lessons; production systems deliver outcomes. The framework outlined in this guide provides a roadmap for organizations ready to make that critical transition and unlock the full potential of their AI investments.
The future belongs to organizations that can move beyond AI experimentation to create reliable, scalable systems that consistently deliver business value. With proper planning, disciplined execution, and commitment to operational excellence, any organization can successfully scale AI solutions from promising prototypes to transformative production systems.
More Blog Posts

AI Agents: The Next Generation of Business Software Transforming Operations
Discover how AI agents are revolutionizing business operations by transforming software into proactive collaborators that anticipate needs and streamline complex processes autonomously.

AI Testing: How to Structure Proof of Concept Without Wasting Budget
Discover how to effectively structure your AI proof of concept to avoid costly failures, ensuring feasibility, value, and a smooth transition from prototype to production.
AI Product Development Timeline: How Long Does It Really Take to Build an AI Product?
Discover the structured phases of AI product development to set realistic timelines and expectations, ensuring successful outcomes and avoiding common pitfalls.